LaMP: When Large Language Models Meet Personalization
LaMP: When Large Language Models Meet Personalization, Salemi et al., ACL’24
This is a seminal paper in the field of personalized large language models, or PLLMs. Personalization has become of broad importance over the past couple decades. From recommendation engines (Netflix, Amazon, TikTok, Youtube, etc) to personalized search, there’s general recognition that the best answer to a question is dependent on the user. Yet generative language models are generally one-size-fits-all, where a single trained model is going to be used to answer questions from all users, regardless of their individual preferences. Enter LaMP: the first comprehensive benchmark for LLMs for the creation of personalized outputs.
The big idea here is that the fundamental unit of evaluation for a PLLM is different than that of an LLM. Where an LLM has canonically correct question/answer tuples, a PLLM instead has question/answer/user-profile triples. This is to say that for any given PLLM question, the correct answer is dependent on who’s asking. In order to judge how well a PLLM personalizes, the authors choose to evaluate a PLLM based on its ability to use user history to accurately predict user behavior. For example, given a user’s history of product ratings and reviews, the PLLM will be asked to predict what rating the user will give with their next review.
That’s a big, noisy, ask! Users are non-deterministic, so this is not a benchmark likely to be saturated. Additionally, personalization is such a large subject area that a broad variety of ‘personalization’ tasks can’t even be analyzed in the same fashion. While product ratings can be easily compared between expected vs. actual, how can we judge accuracy for a ‘title the email’ personalization task? In order to create a comprehensive personalization benchmark, the authors have to identify broad personalization categories, and identify relevant datasets and appropriate methods of evaluation for each.
I love LaMP - details of the LaMP benchmark
The actual benchmark spans seven categories across both text-classification and text-generation tasks, and evaluates the success of personalization for both new- and existing-user use-cases for each category. Finally, it attempts to improve upon these results by introducing two retrieval-augmented solutions for personalization, which achieves some level of improvement over non-personalized performance.
Personalization is judged across the following categories:
- personalized text classification: citation identification, movie tagging, product ratings
- personalized text generation: news headline generation, scholarly title generation, email subject generation, tweet paraphrasing
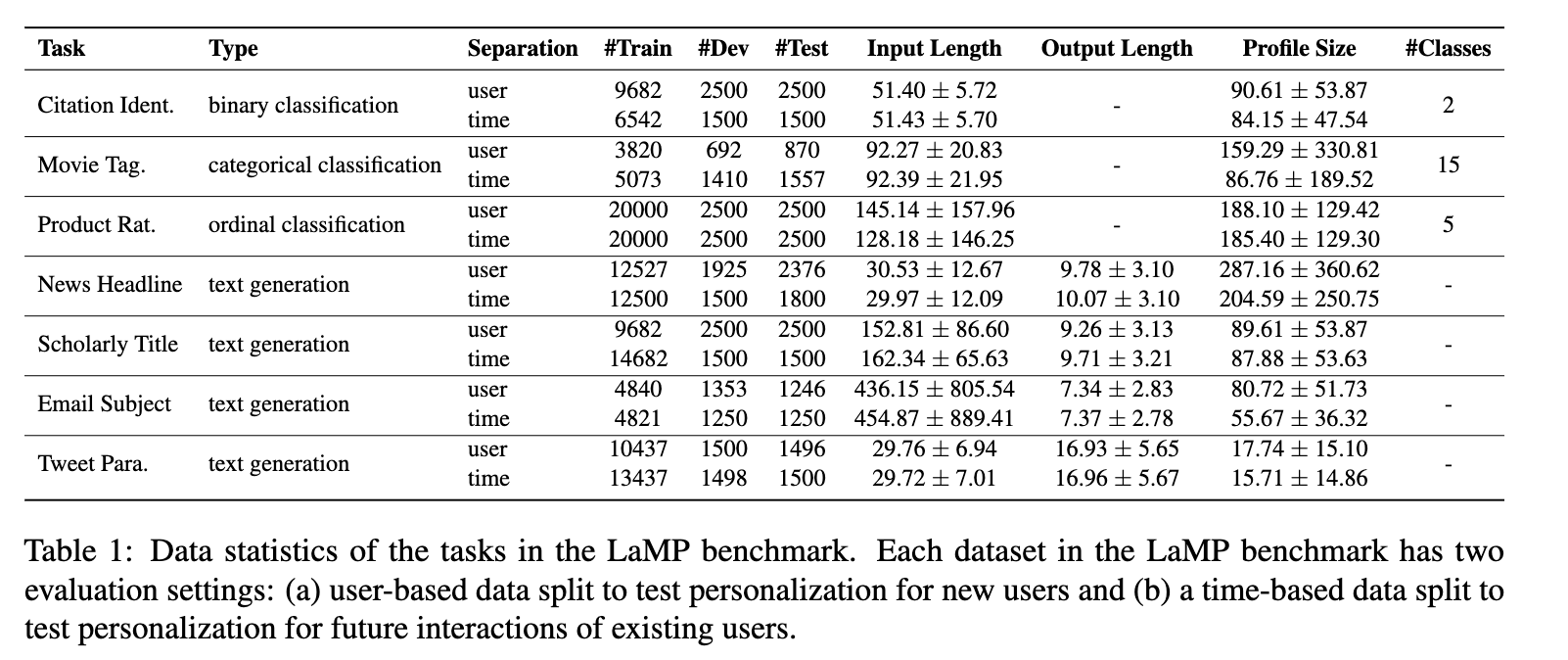
This represents a pretty broad swath of use-cases: binary classification (choosing one of two citations to include), categorical classification (tagging movies within categories), ordinal classification (1-5 star product ratings) and text generation. For the text generation tasks, it was unclear to me why these specific tasks were chosen, or if each task had any specific characteristics which made them unique from the others. One exception is LaMP-6, which is the only dataset which is not publicly available - as this benchmark has become more commonly used, LaMP-6 should be more resistant to pretraining contamination. The text generation tasks all follow the pattern of ‘given a large text, predict the user-generated corresponding small text’.
Evaluation of the tasks is dependent on the task type:
For evaluating classification tasks, we use Accuracy for LaMP-1 (balanced binary classification), Accuracy/F1 for LaMP-2 (multi-class classification), and MAE/RMSE for LaMP-3 (ordinal multi-class classification). Following previous works (Zhou and Bhat, 2021; Panthaplackel et al., 2022) on text generation, we use Rouge-1/Rouge-L (Lin, 2004) as evaluation metrics for the text generation tasks (LaMP-4 to LaMP-7).
This really brought home to me the sheer surface area which falls under the umbrella of ‘personalization’ - these tasks are all sufficiently disparate that they can’t even share a common judge.
Personalization: does it work?
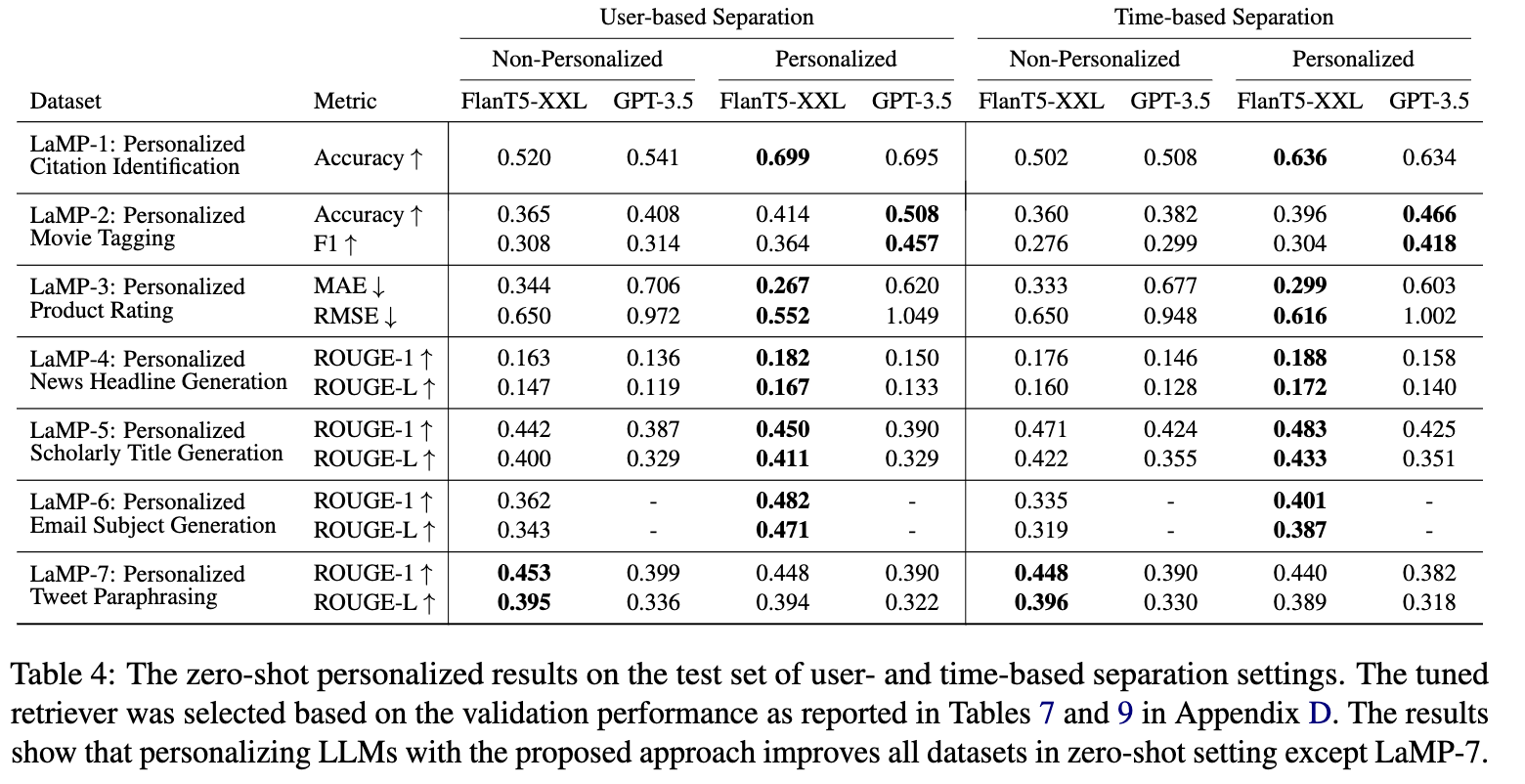
With newly-created benchmark in hand, the authors attempt to demonstrate the efficacy of personalization at improving LLMs’ performance on these personalization tasks. Given the impracticalities of fine-tuning an LLM for each individual user at scale, they focus on retrieval augmentation approaches towards personalization.
There’s a broad variety of experiments performed. They try multiple different retrival-augmentation approaches, In-Prompt Augmentation (IPA) and Fusion-in-Decoder (FiD), with some interesting tradeoffs:
Note that, IPA and FiD offer different tradeoffs. FiD necessitates training of the language model while IPA may be applied without training. Further, while FiD can only be used with encoder-decoder models, IPA can be used across architectures. However, FiD allows us to incorporate more items from the user profile into the LLM’s input.
…across a variety of choices of retrieval models:
…a strong term matching model, BM25 (Robertson et al., 1995), a state-of-the-art pre-trained dense retrieval model, Contriever (Izacard et al., 2022), a retrieval model that returns most recent profile entries in descending order (i.e., Recency), and a Random document selector from the user profile
…and across two separate scenarios representing existing users (T) vs new users (U), who suffer from the ‘cold start’ problem.
Overall, personalization was a success even when the personalization strategy was minimal: even a random selection of documents from the user profile with a personalization prompt led to improved performance on the benchmark compared to a non-personalized prompt. Yet there wasn’t a single winner here: in general IPA outperformed FiD on text generation tasks, but FiD did better on the text classification tasks. Same with the retrieval augmentation approaches: Contriever did consistently well, but was actually beaten by the simple recency-based document selector for the News Headline Generation task (LaMP-4T).
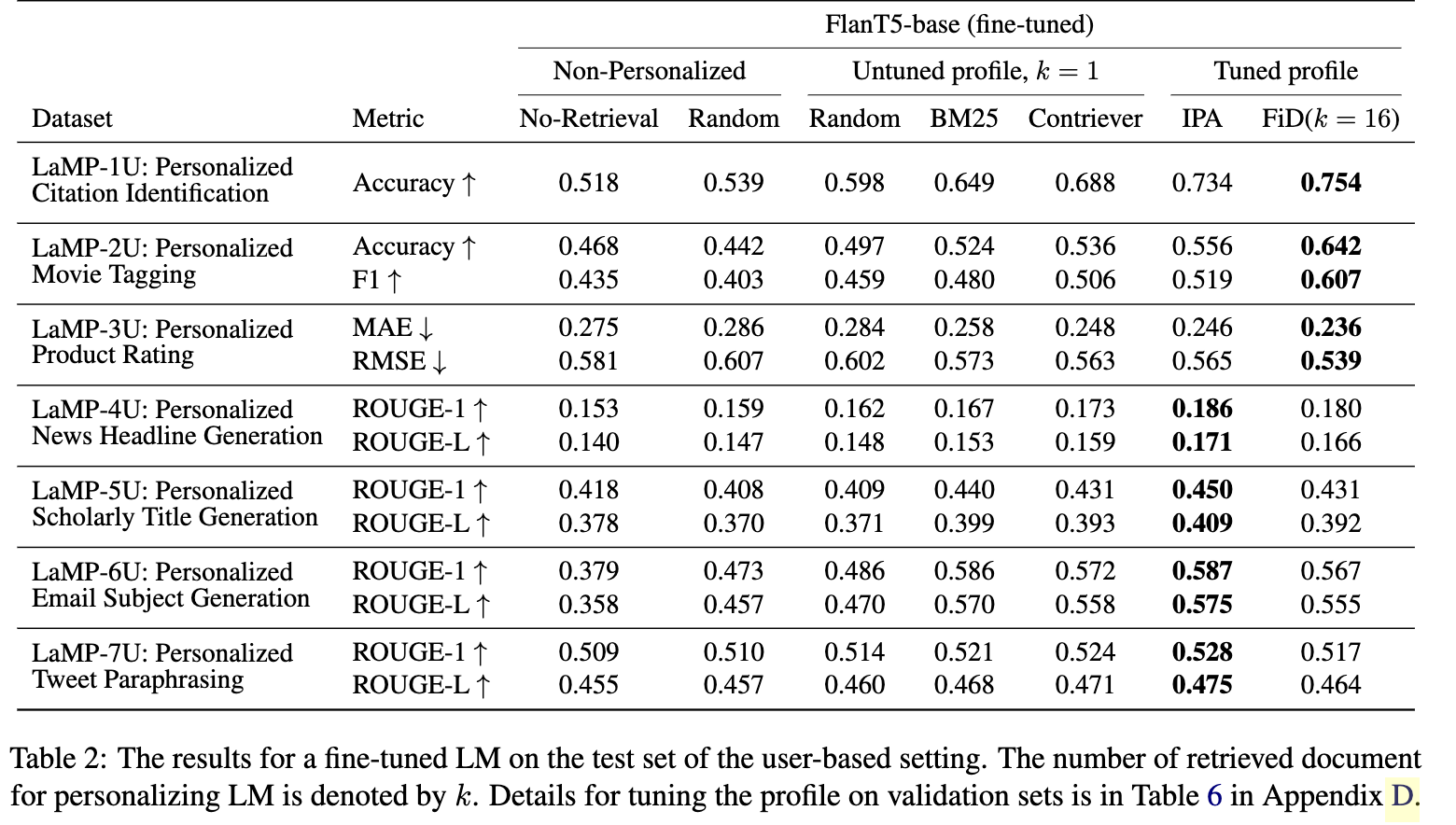
There is some variety across the different experiments - IPA performs better on the time-based setting than FiD on LaMP-1T, in a reversal of their LaMP-1U performance:
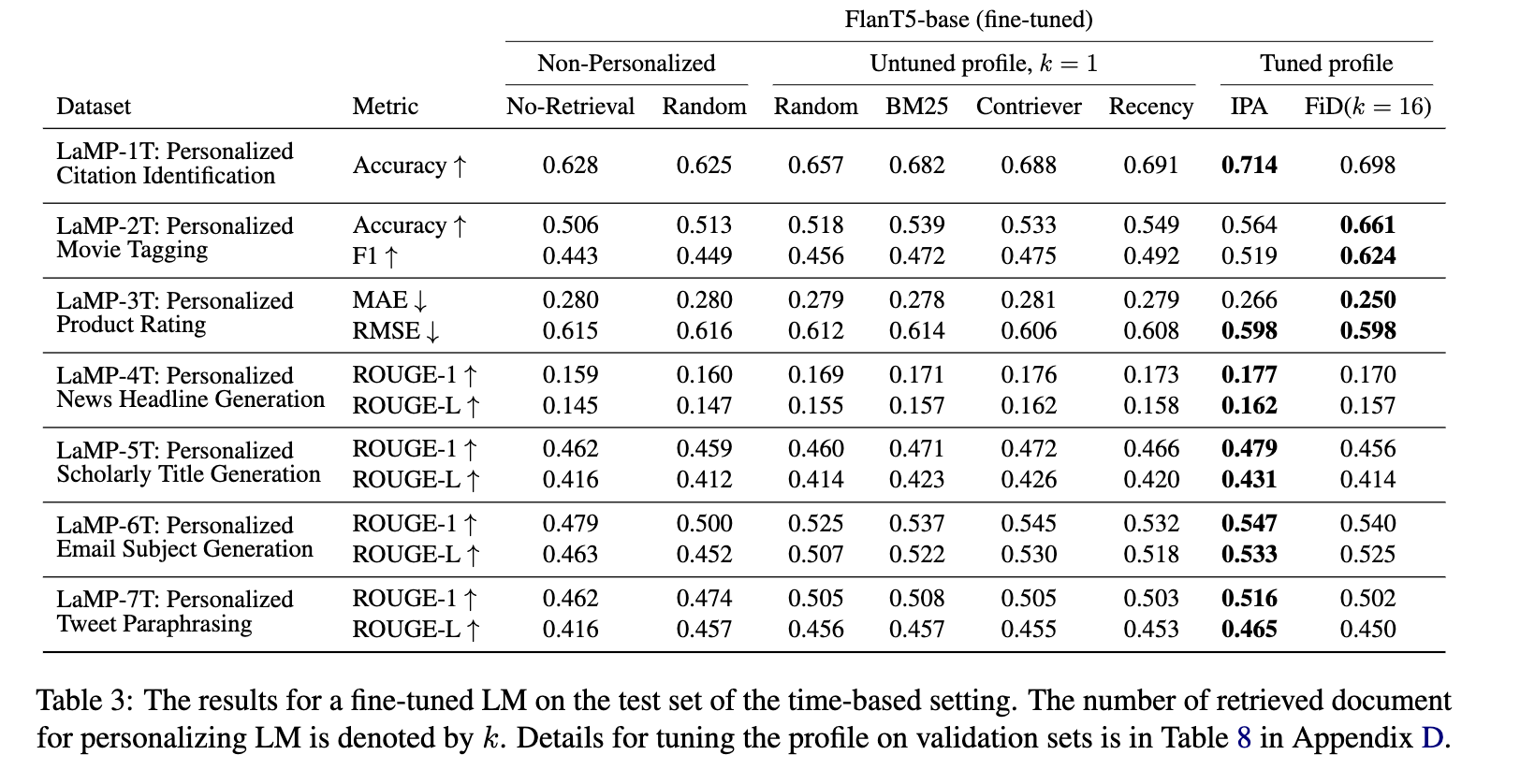
The big takeaway here isn’t that the personalization is solved, and a correct approach found: instead it’s that personalization works, and this benchmark (along with some simple personalization approaches as a proof-of-concept) proves it. They identified a variety of tasks where LLMs can be measured to perform poorly, and with some fairly basic improvements were able to demonstrate significant performance gains - 12.2% average relative performance improvements for the zero-shot setting, and 23.5% with fine-tuning.
One-size fits none?
Reading through this paper, the one-size-fits-all approach of modeling and evaluation reminds me of a common critique of AI prose. Despite AI prose being highly optimized by LLM leaderboards (perhaps even above correctness, see Style Over Substance: Evaluation Biases for Large Language Models) users don’t actually seem happy with AI prose! Common complaints include excessive emoji usage, verbosity, and flattery.
I would argue that these complaints are actually revealing a preference mismatch between the communication preferences of the training dataset / leaderboard users and the communication preferences of the end user. There is no single correct AI voice in the same way that there is no single correct musical genre - it’s subject to individual taste, and fitting that taste is what LaMP looks to measure.
What’s next
So with problem identified and benchmark in hand, what’s next? The authors propose a few areas where research might be focused: personalization via soft prompts, generating personalization prompts based on the user profile (instead of retrieval), etc., but these are not fully fleshed out. Instead think of it as an open-ended question: how can we improve personalization performance? Given the broad variety of winning strategies on the benchmark so far, the answer may be an ensemble approach, where the LLM attempts to determine which type of personalization is required and routes to a corresponding correct personalization strategy accordingly…or maybe we just have yet to come across the perfect solution.
One additional area I’ll be paying attention to: what is the efficacy of internal personalization approaches vs external personalization approaches? Is it possible to achieve best-in-class results using only RAG + prompt modifications, or will that be outclassed by fine-tuning-based approaches? If internal approaches continue to outperform external approaches, that could be a major advantage for Google/Facebook as the only frontier model providers already sitting on top of massive user preference datasets.
The good news is this seminal paper is now two years old, giving us a number of new approaches to evaluate against our personalization benchmark.